Step 1: Please install Scala/SBT Plugin in your IntelliJ IDE (File --> Settings --> Plugins) Step 2: New Project --> Scala --> SBT
Step 3: Select SBT Version and Scala VersionWait Until the Entire Project Folder (with Src,Target,folders,etc) are Established after you created the Project.
Step 4: Create a assembly.sbt under project folder. You might want this Plugin to create aUBER Jar for your application.
resolvers += Resolver.url("artifactory", url("http://scalasbt.artifactoryonline.com/scalasbt/sbt-plugin-releases"))(Resolver.ivyStylePatterns)
addSbtPlugin("com.eed3si9n" % "sbt-assembly" % "0.13.0")
 Step 5:
You can look for a complete and latest build.sbt file here
Add Dependencies as below in build.sbt file
Step 5:
You can look for a complete and latest build.sbt file here
Add Dependencies as below in build.sbt file
name := "MyFirstSparkProject"
version := "1.0"
scalaVersion := "2.10.4"
libraryDependencies ++= Seq(
"org.apache.spark" % "spark-core_2.10" % "1.6.0" exclude ("org.apache.hadoop","hadoop-yarn-server-web-proxy"),
"org.apache.spark" % "spark-sql_2.10" % "1.6.0" exclude ("org.apache.hadoop","hadoop-yarn-server-web-proxy"),
"org.apache.hadoop" % "hadoop-common" % "2.7.0" exclude ("org.apache.hadoop","hadoop-yarn-server-web-proxy"),
"org.apache.spark" % "spark-sql_2.10" % "1.6.0" exclude ("org.apache.hadoop","hadoop-yarn-server-web-proxy"),
"org.apache.spark" % "spark-hive_2.10" % "1.6.0" exclude ("org.apache.hadoop","hadoop-yarn-server-web-proxy"),
"org.apache.spark" % "spark-yarn_2.10" % "1.6.0" exclude ("org.apache.hadoop","hadoop-yarn-server-web-proxy")
)
 Step 6:
Remove the unwanted libraries. Choose the proper version of the libraries if you get into this warning. But this step is optional.
Step 6:
Remove the unwanted libraries. Choose the proper version of the libraries if you get into this warning. But this step is optional.
 Step 7:
Look at the dependencies below in the Open Module Settings under src folder. Right click the src and Select Open Module Settings.
Step 7:
Look at the dependencies below in the Open Module Settings under src folder. Right click the src and Select Open Module Settings.
 Step 8:
Right Click src folder and choose Scala Class. Select Singleton Object class.
Step 8:
Right Click src folder and choose Scala Class. Select Singleton Object class.
 Step 9:
Write this Program as below.
Step 9:
Write this Program as below.
import org.apache.spark.{SparkContext, SparkConf}
/**
* Created by Giri R Varatharajan on 9/8/2015.
*/
object SparkWordCount {
def main(args:Array[String]) : Unit = {
System.setProperty("hadoop.home.dir", "D:\\hadoop\\hadoop-common-2.2.0-bin-master\\")
val conf = new SparkConf().setAppName("SparkWordCount").setMaster("local[*]")
val sc = new SparkContext(conf)
val tf = sc.textFile(args(0))
val splits = tf.flatMap(line => line.split(" ")).map(word =>(word,1))
val counts = splits.reduceByKey((x,y)=>x+y)
splits.saveAsTextFile(args(1))
counts.saveAsTextFile(args(2))
}
}
You might want to download the winutils.exe from web. This exe file would act as ahadoop client to communicate with the Windows Sytem. In case of Unix, this is not required.
args(0) --> Input File
args(1) --> Output File 1
args(2) --> Output File 2
Let's create a package to run this Program through Spark-Submit.
Step 10:
Install Sbt from this link SBT Downloads and Include the bin folder of the extracted package to the Class Path.
In case of UNIX, use EXPORT SBT_HOME='/etc/sbt/bin'
Type sbt clean package against the MyFirstSparkProject folder

 After this you can see a packaged jar created under target directory.
After this you can see a packaged jar created under target directory.
 Step 11:
Let's submit the Spark Job. Enter the below command under the bin directory of your Spark Installed directory. You can install spark in this link Spark Downloads
Choose Pre Built Hadoop Version package. Extract to any location in your hard drive.
Step 11:
Let's submit the Spark Job. Enter the below command under the bin directory of your Spark Installed directory. You can install spark in this link Spark Downloads
Choose Pre Built Hadoop Version package. Extract to any location in your hard drive.
D:\Spark\spark-1.5.0-bin-hadoop2.6\bin>spark-submit --class SparkWordCount --master local[*] D:\typesafe-activator-1.3.7-minimal\activator-1.3.7-minimal\MyFirstSparkProject\target\scala-2.10\myfirstsparkproject_2.10-1.0.jar D:\Spark\spark-1.6.0\README.md D:\Spark\spark-1.6.0\CountOutput D:\Spark\spark-1.6.0\SplitOutput
Step 12: Check the Output in the Output directory mentioned in the Spark-submit command above.

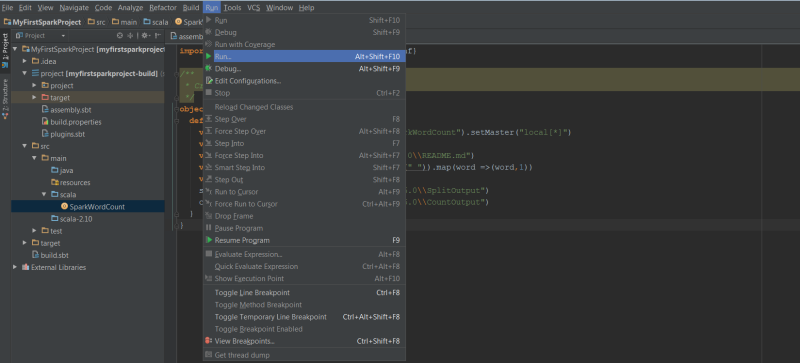
You can open the part files and check the Word Count Output. Another Option to Execute the Same Job through Run command of IntelliJ Program:
import org.apache.spark.{SparkContext, SparkConf}
/**
* Created by Giri R Varatharajan on 9/8/2015.
*/
object SparkWordCount {
def main(args:Array[String]) : Unit = {
System.setProperty("hadoop.home.dir", "D:\\hadoop\\hadoop-common-2.2.0-bin-master\\")
val conf = new SparkConf().setAppName("SparkWordCount").setMaster("local[*]")
val sc = new SparkContext(conf)
val tf = sc.textFile("D:\\Spark\\spark-1.6.0\\README.md")
//val tf = sc.textFile(args(0))
val splits = tf.flatMap(line => line.split(" ")).map(word =>(word,1))
val counts = splits.reduceByKey((x,y)=>x+y)
splits.saveAsTextFile("D:\\Spark\\spark-1.6.0\\SplitOutput")
counts.saveAsTextFile("D:\\Spark\\spark-1.6.0\\CountOutput")
}
}

Exception 1: If you end up with the below exception, download the winutils.exe file. This file will serve as a hadoop client to your Spark Job. Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties 16/02/02 21:55:19 INFO SparkContext: Running Spark version 1.6.0 16/02/02 21:55:19 ERROR Shell: Failed to locate the winutils binary in the hadoop binary path Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties 16/02/02 21:55:19 INFO SparkContext: Running Spark version 1.6.0 16/02/02 21:55:19 ERROR Shell: Failed to locate the winutils binary in the hadoop binary path java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries. at org.apache.hadoop.util.Shell.getQualifiedBinPath(Shell.java:356) at org.apache.hadoop.util.Shell.getWinUtilsPath(Shell.java:371) at org.apache.hadoop.util.Shell.<clinit>(Shell.java:364) at org.apache.hadoop.util.StringUtils.<clinit>(StringUtils.java:80)
Exception 2: Move the javax.servlet.api-jar to the last in the Dependency window or Just remove this Dependency. Otherwise, you can provide the below in your build.sbt file.
"org.apache.spark" % "spark-core_2.10" % "1.6.1" excludeAll ExclusionRule(organization = "javax.servlet"),
java.lang.SecurityException: class "javax.servlet.FilterRegistration"'s signer information does not match signer information of other classes in the same package at java.lang.ClassLoader.checkCerts(ClassLoader.java:895) at java.lang.ClassLoader.preDefineClass(ClassLoader.java:665) at java.lang.ClassLoader.defineClass(ClassLoader.java:758) at java.security.SecureClassLoader.defineClass(SecureClassLoader.java:142) at java.net.URLClassLoader.defineClass(URLClassLoader.java:467

After this execute the Program Run option. You can see the output. You can run anyAPIs on SQLContext without any issues. Please note You don't need to setup Hive or Spark in your local machine in order to run the application through IntelliJ IDE. The execution process automatically creates metastore_db folder in your project directory and will process all Hive related things under a warehouse directory. But still I would recommend to use your local Linux Sandbox cluster for HiveContext or for Spark SQL DataFrames, etc.
Happy Sparking 🙂

Hello,
First thank you for this tutorial, but i’ve got a problem while executing this code i have an error. Here is the output:
Using Spark’s default log4j profile: org/apache/spark/log4j-defaults.properties
16/02/11 09:44:18 INFO SparkContext: Running Spark version 1.6.0
Exception in thread “main” java.lang.NoClassDefFoundError: scala/collection/GenTraversableOnce$class
at org.apache.spark.util.TimeStampedWeakValueHashMap.(TimeStampedWeakValueHashMap.scala:42)
at org.apache.spark.SparkContext.(SparkContext.scala:298)
at SparkWordCount$.main(SparkWordCount.scala:29)
at SparkWordCount.main(SparkWordCount.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at com.intellij.rt.execution.application.AppMain.main(AppMain.java:140)
Caused by: java.lang.ClassNotFoundException: scala.collection.GenTraversableOnce$class
at java.net.URLClassLoader$1.run(URLClassLoader.java:366)
at java.net.URLClassLoader$1.run(URLClassLoader.java:355)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:354)
at java.lang.ClassLoader.loadClass(ClassLoader.java:425)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:308)
at java.lang.ClassLoader.loadClass(ClassLoader.java:358)
… 9 more
Process finished with exit code 1
LikeLike
Can u send me the code u have written?
LikeLiked by 1 person
Have the same problem. Can you tell me wat was the solution?
LikeLike
spark-submit option is not working , my project in intelliJ looks like this
package tlf
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author ${user.name}
*/
object FormatDataTlf {
LikeLike
It’s great , thanks a lot.
LikeLike